Wie ticken Datenbanken?




Der ehemalige CEO von Xing und Vice President von eBay Stefan Gross-Selbeck hat einmal gesagt: “Daten sind das Öl des 21. Jahrhunderts.” Und wir stimmen ihm da hundertprozentig zu: Ohne Daten ist unsere Welt nicht mehr vorstellbar und mit Daten kann man inzwischen richtig viel Geld verdienen. Deswegen ist die Thematik Datenbanken auch so wichtig.
Aber was genau sind Datenbanken überhaupt?
Jeder kennt Excel-Tabellen oder vielleicht hast du jemanden im Bekanntenkreis der zum Beispiel seine Rezepte fein säuberlich in einem Karteikartenkasten sortiert hat. Datenbanken sind da ähnlich: Sie sind der Versuch einen Ausschnitt der realen Welt im Rechner abzubilden.
Doch was sind Daten eigentlich? Im Grunde sind sie nichts anderes als Informationen und die Datenbank ist dazu da, um diese Informationen zu speichern. An diese Speicherung sind natürlich gewisse Anforderung gestellt:
Zunächst soll diese Speicherung performant also leistungsfähig sein. Als nächstes müssen die Informationen strukturiert gespeichert werden, sodass man jederzeit genau die Information wiederfindet, die man gerade braucht. Auch die Tante Erna mit ihren Rezeptkarteikarten hat diese zumindest alphabetisch sortiert.
Zudem sollte die Speicherung effizient sein: Einmal in Bezug auf die Speichergröße und auch auf die Laufzeit. Man möchte nicht eingeschränkt sein, wenn es darum geht, wie viele Daten man speichert oder wie lange es dauert, bis man Zugriff auf die Daten hat.
Des Weiteren soll eine Integrität der Daten gegeben sein: Es dürfen keine Fehler oder Dopplungen vorkommen, die gespeicherten Daten sollten plausibel sein und am besten wäre es, wenn all dies bereits bei der Eingabe der Daten überprüft wird.
Und als letztes und wichtigstes Kriterium sollte die Datenspeicherung natürlich absolut sicher vonstatten gehen, sodass nichts verloren geht und keine Unbefugten Zugriff darauf erhalten. Tante Erna möchte ja auch keine Rezepte verlieren, weil ihr Karteikasten ein Loch hat. Und wenn sie besonders geheimniskrämerisch ist, macht sie sogar noch ein Schloss dran. Doch genug von unserer Lieblingstante Erna.
Relationale Datenbanken
Kommen wir zur am häufigsten verwendeten Form der Datenbanken: Die relationalen Datenbanken. Relational bedeutet soviel wie “in Beziehung stehend” oder “eine Beziehung darstellend”. Und genau das ist auch der Kerngedanke einer relationalen Datenbank: Die Daten werden in Beziehungen zueinander dargestellt. Ein Beispiel aus der Beraterwelt hierzu wäre eine Datenbank, in der Informationen zu Unternehmen und IT-Consultants abgespeichert werden. Und die Relation zwischen diesen beiden unterschiedlichen “Daten-Gruppen” könnte “Kunde sucht Consultant” oder “Consultant arbeitet bei Kunde” sein. Bekannte Systeme, die relationale Datenbanken darstellen, sind Microsoft SQL Server, OracleDB, DB2 von IBM, SQLite, MariaDB und MySQL, wobei die letzten drei nicht kommerziell sondern frei verfügbar sind.
Doch wie kann man sich den Aufbau solcher “Daten-Gruppen” vorstellen? Zunächst einmal gibt es natürlich die Datenbank und – um beim Beratungsszenario zu bleiben – nennen wir diese consulting (s. unten). Der doppelte Oreo-Keks links im Bild ist übrigens das klassische Symbol, um Datenbanken darzustellen, beispielsweise in UML-Diagrammen. Diese Datenbank besteht aus beliebig vielen Tabellen, zum Beispiel die Tabellen consultants oder companies, welche je nach Anwendungsfall in Relation zueinander gebracht werden können. Und in diesen Tabellen sind alle Daten strukturiert nach Objekttyp gespeichert.
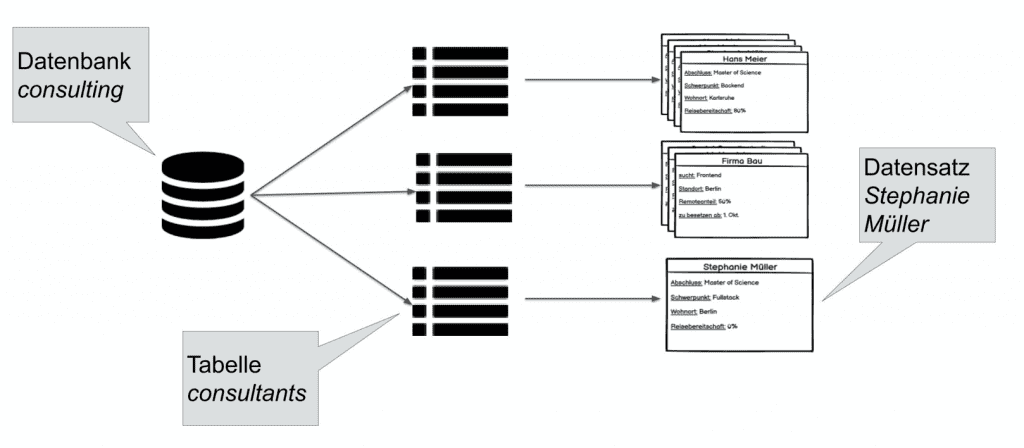
Natürlich sind solche Datensätze keine Karteikarten sondern lediglich Zeilen in den Tabellen mit beliebig vielen Spalten, je nachdem wie viele Eigenschaften zu den einzelnen Datensätzen gespeichert werden sollen.
Wie oben schon erwähnt soll diese Speicherung strukturiert sein. Diese Anforderung wird mit Hilfe von Restriktionen und Regeln für die Spalteninhalte gelöst. So dürfen je Spalte bzw. Eigenschaft nur bestimmte Datentypen eingetragen werden, die je nach Definition der Datenbank noch eigenen Regeln unterliegen. Beispielsweise darf in der untenstehenden Tabelle consultants in der Spalte Name, die selbstverständlich für die Namen der Consultants angedacht ist, nur Text eingetragen werden. Oder in der Spalte Reisen, welche die Reisebereitschaft eines Consultants darstellt, sind nur ganze Zahlen von 0 bis 100 erlaubt.

Dem aufmerksamen Leser dürften nun schon gewisse Funktionalitäten einer Datenbank ins Auge gestochen sein. Diese lassen sich auf die vier fundamentalen Operationen im Datenbank-Geschäft herunterbrechen, welche häufig unter dem Akronym CRUD auftauchen:
- Create: Datenbanken erstellen/ Daten eintragen
- Read: Daten auslesen/suchen/filtern
- Update: Daten aktualisieren/bearbeiten
- Delete: Daten löschen.
Wichtig zu beachten ist an dieser Stelle, dass Tabellen einer relationalen Datenbank in sich nicht sortiert sind. Es wird also nicht registriert, in welcher Reihenfolge Daten eingetragen, verändert oder gelöscht werden. Allerdings gibt es durchaus die Möglichkeit bei der Suche und dem Filtern von Daten das Ergebnis zu sortieren. Dies hat aber keinerlei Einfluss auf den Inhalt der Datenbank. Gleiches gilt für die Reihenfolge der Spalten.
Wichtige Prinzipien der relationalen Datenbanken
Um die anfangs beschriebenen Anforderungen an eine Datenbank sicherzustellen, gibt es gewisse Prinzipien, die es bei relationalen Datenbanken zu beachten gilt.
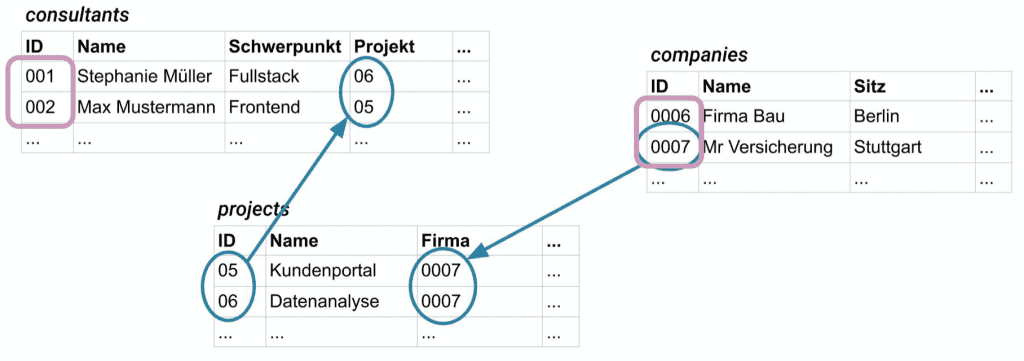
Da wären zum einen Primär- und Fremdschlüssel und weil wir ITler so gern englisch sprechen, sagt man auch primary key und foreign key. Der primary key ist die ID eines Datensatzes und zur eindeutigen Identifizierung dessen da. Der foreign key ist nichts anderes als die ID eines anderen Datensatzes, der mit diesem Datensatz in einer Beziehung steht. Kompliziert? Hier kommt ein Beispiel:
Unten siehst du drei Tabellen: Consultants, companies und projects. Die pink markierten Felder sind die primary keys und die blau markierten Einträge zeigen auf die foreign keys. So steht in der Spalte Projekt der Tabelle consultants die Information, in welchem Projekt der jeweilige Consultant gerade arbeitet. Und damit diese Information eindeutig ist, trägt man die jeweilige ID ein, die der entsprechende Datensatz des Projekts hat. Gleiches gilt für die Spalte Firma der Tabelle projects, in der die IDs der Unternehmen eingetragen sind, welche die Projekte initiiert haben.
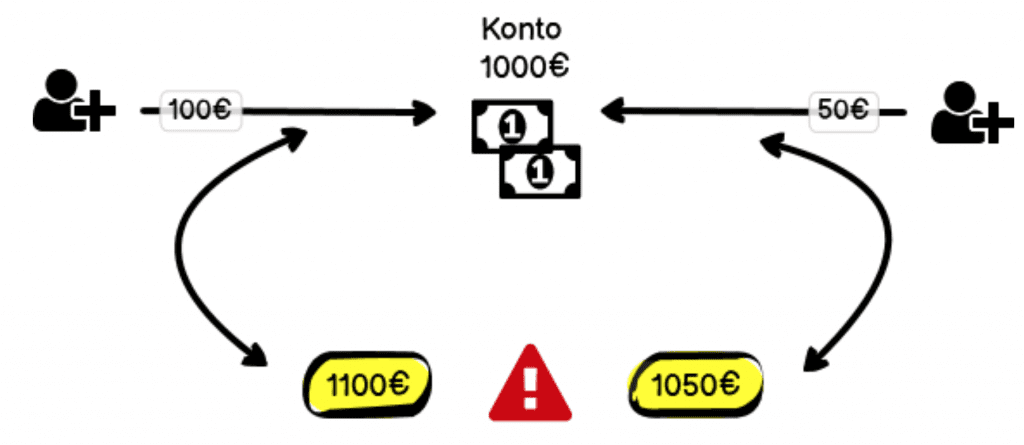
Ein weiteres wichtiges Prinzip sind Transaktionen. Hierfür kann man wundervoll auf ein Beispiel aus der Bankenwelt zurückgreifen: Das Bankkonto. Stell dir vor, die Eheleute Erna und Heinz Schmidt haben ein gemeinsames Bankkonto, auf dem 1000€ drauf sind. Wie der Zufall es nun mal so will, zahlen beide zur gleichen Zeit an unterschiedlichen Automaten Geld ein: Erna 100,- und Heinz nur 50,- (wahrscheinlich hat der Kavalier seiner Erna noch was schönes zum Geburtstag gekauft). Wie ist diese Transaktion “Geld einzahlen” nun aufgebaut? Als erstes fragt der Automat, an dem Erna steht, den Kontostand ab: 1000€ sagt er. Gleichzeitig sagt Heinz’ Automat dasselbe. Jetzt zahlt Erna ihre 100€ und Heinz seine 50€ ein und beide Automaten speichern den neuen Kontostand. Bei Erna steht jetzt ein neuer Kontostand von 1100€ und bei Heinz sind es 1050€. Und schon haben wir den Salat mit unterschiedlichen Kontoständen, verschwundenem Geld und alles würde drunter und drüber gehen. Zum Glück ist das in der Realität nicht so. Denn in Wirklichkeit dürfen Transaktionen nicht kreuz und quer und durcheinander ausgeführt werden, sondern müssen schön der Reihe nach abgearbeitet werden. Und solange eine noch nicht fertig ist, ist das Konto für Änderungen gesperrt und die anderen Transaktionen müssen warten.
Dieses Prinzip, das den Transaktionen die Spielregeln vorgibt, ist das ACID-Prinzip. Dies steht für Folgendes:
- Atomicity = Transaktionen werden entweder komplett oder gar nicht ausgeführt.
- Consistency = Eine Transaktion überführt eine Datenbank immer von einem konsistenten Zustand in einen anderen konsistenten Zustand. Anders ausgedrückt: Eine Transaktion darf keine fehlerhaften Zustände hervorrufen.
- Isolation = Immer nur eine: Transaktionen dürfen in ihrer Ausführung nicht durch parallel ausgeführte Befehle beeinträchtigt werden.
- Durability = Wird eine Transaktion erfolgreich ausgeführt, wird das Ergebnis dauerhaft in der Datenbank gespeichert.
Und somit geht alles seinen richtigen Gang: die Eheleute Schmidt haben ihr Geld ordentlich zur Bank gebracht und können nun Tante Ernas Geburtstag feiern. Die Lösung des korrekten Kontostands am Ende des Tages wird hier nicht verraten. 😉






